《程序员的 README》

[美] 克里斯·里科米尼(Chris Riccomini)/ [美] 德米特里·里亚博伊(Dmitriy Ryaboy)
2023-7-10
译者序:“翻译完本书的最后一章时,正好是我踏入软件行业的12年整,此时的我却觉得自己的职业生涯好像才刚刚开始。”
有些地方的翻译好像有点怪怪的…
程序员的 README
第1章 前面的旅程
目的地 ☸️
- 技术知识
- 执行力
- 沟通能力
- 领导力
地图 🗺
- 新手营
- 试炼之河
- 贡献者之角
- 运维之海
- 胜任之湾
第2章 步入自觉阶段
学习如何学习
- 虽然说持续进步非常重要,但是把所有清醒的时间都花在工作上是不健康的
- 在工作的前几个月里,你要学习一切如何运作
- 错误是不可避免的。如果你失败了,也不要被击垮:写下经验教训,然后继续前行
- 调试器是你运行实例代码时最好的朋友
- 在复杂的情况下,特别是在多线程的应用程序中,输出调试信息可能会产生误导
- 不要试图一下子把所有东西都读完。请从团队文档和设计文档入手
- 不要像阅读小说一样从前到后地通读代码:请利用你的IDE来浏览代码
- 出版物大多很可靠,只是有些过时。在线资源则正好相反,不那么可靠,但很能跟上潮流
- 跟随一名高级工程师是学习新技能的好方法
- 从长远来看,获得明确的信息将保护你免受挫折(be careful
提出问题
- 有效地提出问题将帮助你快速地学习,而不会烦扰其他人
- 动手调查
- 设置一个时间限制
- 写下全过程
- 别打扰别人
- 多用“非打扰式”交流
- 批量处理
克服成长的障碍
- 冒充者综合征 — “有意识的无能力”
- 邓宁-克鲁格效应 — “无意识的无能力”
行为准则
需要做的 不应该做的 多尝试和实验代码 只是大量炮制劣质代码 多阅读设计文档和他人的代码 害怕承担风险和失败 参加一些聚会、在线社区、兴趣小组和导师计划 过于频繁地参加研讨会 多读论文和博客 害怕提出问题 多采用“非打扰式”交流 旁听面试以及参与软件的熵轮换
第3章 玩转代码
软件的熵
- 这种走向无序的趋势被称为软件的熵(software entropy)
- 持续的重构可以减少熵
技术债
技术债是为了修复现有的代码不足而欠下的未来工作
鲁葬的 谨慎的 有意的 ““我们没有时间去设计” ““让我们先发布再处理后续” 无意的 “什么是分层结构?” “现在我们知道了当时应该怎么做” 技术债总是不可避免的,因为你无法防止无意中的错误
技术债甚至可能是成功的标志:项目只有存活了足够长的时间,才会变得无序
不要把你的呼吁建立在价值判断上(“这代码又老又难看”),将重点放在技术债的成本和修复它带来的好处上
变更代码
- 善于利用现有代码
- 过手的代码要比之前更干净
- 对重构要务实
- 善用 IDE
- 请使用 VCS 的最佳实践
避“坑”指南
- 保守一些的技术选型
- 不要特立独行
- 不要只分叉而不向上游提交修改
- 克制重构的冲动
行为准则
需要做的 不应该做的 进行渐进式的重构 过度使用“技术债”这个词 从新特性的提交中剥离重构的部分 为了适应测试而将变量或方法变成公共的 保持以小规模的方式修改伐码 成为编程语言上的“势利眼” 将过手的代码整理得比之前更干净 忽视你公司的标准和工具集 使用保守的技术选型 只分叉而不向上游提交修改
第4章 编写可维护的代码
防御式编程
- 避免空值
- 保持变量不可变
- 使用类型提示和静态类型检查器
- 验证输入
- 不接受 Word 文档(非纯文本)
- 善用异常,异常要有精确含义
- 早抛晚捕,不能忽略
- 智能重试,何时重试以及重试的频率都需要技巧
- 构建幂等系统,幂等的操作是可以被进行多次并且仍然产生相同结果的操作
- 及时释放资源
关于日志的使用
- 给日志分级
- 日志的原子性,所谓原子日志,就是指在一行消息中包含所有相关的信息
- 关注日志性能
- 不要记录敏感数据
系统监控
- 使用标准的监控组件
- 测量一切
- 资源池
- 缓存
- 数据结构
- CPU 密集型操作
- I/O 密集型操作
- 数据大小
- 异常和错误
- 远程请求和响应
跟踪器
配置相关注意事项
- 配置无须新花样
- 记录并校验所有的配置
- 提供默认值
- 给配置分组
- 将配置视为代码
- 保持配置文件清爽
- 不要编辑已经部署的配置
工具集
行为准则
需要做的 不应该做的 宁愿编译出错,也不要运行出错 在程序逻辑中应用异常 尽可能使事情不可变 在异常处理中只返回错误码 校验输入和输出 捕获你无法处理的异常 学习开放式 Web 应用程序安全项目 (OWASP) 的十大报告 写入带折行的日志 使用 bug 检查工具和类型提示的特性 在日志中记载秘密或敏感的数据 在异常之后清理资源(尤其是端口、文件指针和内存) 单独在某台计算机上手动修改配置 使用系统指标来监控你的代码 在配置文件中存储密码或者秘密信息 让你的程序可以配置 写定制化的配置格式 检验和记录所有的配置 在可以避免的情况下使用动态配置
第5章 依赖管理
依赖管理基础知识
- 相依性是指你的代码所依赖的代码
- 语义化版本(主版本号、次版本号和补丁版本号/微版本号 - 预发布版本)
- 语义化版本同时具有唯一性、可比性、信息性
- 传递依赖
相依性地狱
- 比较常见的相依性地狱的罪魁祸首是循环依赖、钻石依赖和版本冲突
避免相依性地狱
- 隔离依赖项
- 在某些场景下,可以打破 DRY(Don’t Repeat Yourself)原则,将某些导致依赖问题的代码直接拷贝到项目中
- 按需添加依赖项
- 指定依赖项的版本
- 依赖范围最小化
- 保护自己免受循环依赖的影响
- 隔离依赖项
行为准则
需要做的 不应该做的 务必使用语义化版本 使用Git的哈希值当作版本号 明确指定依赖版本的范围 在收益未超过成本时添加依赖项 务必使用依赖关系报告工具来分析传递依赖 直接使用传递来的依赖项 添加新的依赖项时,请务必持怀疑态度 引入循环依赖 精确地使用依赖范围
第6章 测试
测试的多种用途
- 检查代码是否正常工作
- 保护代码不会被将来那些无意中的修改所影响
- 鼓励清爽的代码
- 强迫开发者试用他们自己的 API
- 记录组件之间如何交互
测试类型
- 单元测试
- 集成测试
- 系统测试
- 性能测试
- 验收测试
测试工具
- 模拟库
- 测试框架
- 代码质量工具
- 自己动手编写测试
- 编写干净的测试
- 避免过度测试
测试中的确定性
- 几种可以避免出现非确定性测试的手段
- 用一个常数作为随机数生成器的种子
- 不要在单元测试中调用远程系统
- 采用注入式时间戳
- 避免使用休眠和超时
- 记得关闭网络套接字和文件句柄
- 将网络套接字都绑定到0端口(操作系统会自动选择一个开放的端口)
- 动态地生成唯一的文件路径和数据库位置
- 隔离并清理剩余的测试状态
- 测试不应该依赖于特定的执行顺序
- 几种可以避免出现非确定性测试的手段
行为准则
需要做的 不应该做的 使用测试去重现bug 忽视添加新测试工具时的成本 使用模拟工具去帮助编写单元测试 依赖干他人为你编写测试用例 使用代码质量工具去检查覆盖率、格式和复杂度 仅仅为了提高覆盖率而编写测试 在测试中使用常教种子的随机救生成器 仅仅将代码覆盖率作为代码质量的衡量标准 在测试后关闭网络套接字和文件句柄 在测试中使用可以避免的休眠和超时 在测试中生成唯-的文件路径和数据库位置 在单元测试中调用远程系统 在测试执行的间隙清理掉遗留的测试状态 依赖于测试执行顺序
第7章 代码评审
为什么需要评审代码
- 代码评审是一种教学和学习工具
- 为了安全性与合规性,需要代码评审
- 对代码库的共同理解有助于团队更有凝聚力地扩展代码
当你的代码被评审时
- 代码修改由准备、提交、评审、最后批准和合并这几个环节组成
- 用评审草案降低风险
- 提交评审请勿触发测试
- 预排大体量的代码修改
- 评审意见是针对代码的,而不是针对个人的
- 保持同理心,但不要容忍粗鲁
- 不要羞于要求别人评审你的代码
评审别人的代码时
- 分流评审请求(轻重缓急)
- 给评审预留时间
- 理解修改的意图
- 提供全面的反馈
- 代码修改的正确性、可实施性、可维护性、可读性和安全性
- 要承认优点
- 区分问题、建议和挑剔
- 在反馈前加上字样
- “可选” (optional)
- “接受或不接受” (take it or leave it)
- “非必须” (nonblocking)
- 不要只做橡皮图章
- 不要只局限于使用网页版的评审工具
- 不要忘记评审测试代码
- 推动决断(不要拖)
行为准则
需要做的 不应该做的 在提交评审请求之前保证通过了测试和代码检测工具的检查 仅仅为了触发持续集成(CI)系统而提交评审请求 为代码评审预留出专门的时间,像对待其他工作–样对待评审工作 只做橡皮图章 当评审意见很粗鲁、没有建设性或者有不当言论的时候,请明确指出来 和代码“坠入爱河”或者把评审的反馈意见当作私人恩怨 通过适当提供相应修改的背景信息来帮助评审者 在不了解整项政动的大背景的情况下就直接纠缠代码细节 在进行代码评审时,超越肤浅的对代码风格的指摘 过度地挑剔 用尽一切工具去理解棘手的代码改动,不要只依赖评审工具自身的界面 让“完美”成为“优秀”的敌人 将测试代码纳入评审范围
第8章 软件交付
软件交付流程
- 构建、发布、部署 和
展开(上线、投产)
- 构建、发布、部署 和
分支策略
- 频繁地合并被称为持续集成(CI)
构建环节
- 打包需要带版本号
- 将不同的资源单独打包
发布环节
- 请勿只想着发布
- 将包发布到仓库
- 保持版本不变性
- 频繁发布
- 对发布计划保持透明
- 撰写变更日志和发行说明
部署环节
- 自动部署
- 部署的原子性
- 独立地部署应用
上线环节
系统监控
- 特性开关
- 熔断器
- 并行的服务版本梯队
- 金丝雀部署(金丝雀报警器)
- 蓝绿部署
摸黑启动(灰度发布)
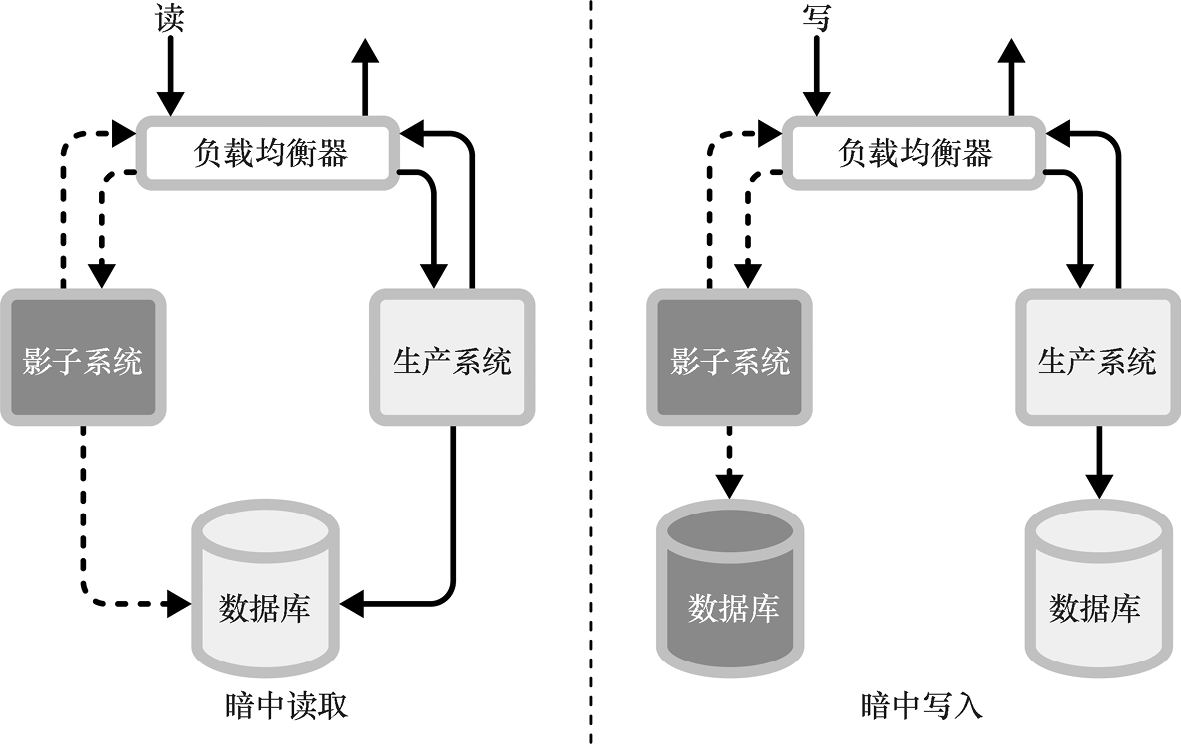
行为准则
需要做的 不应该做的 使用基于主干的分支模式并在可能的条件下持续集成 发布未署版本号的包 使用 VCS 工具来管理分支 把配置、模式、图片和语言包–并打包在一起 与发布和运维团队合作为你的应用建立正确的流程 盲目地依赖发布经理和运维团队 一并发布变更日志和发行说明 使用 VCS 来分发软件 在新版发布时通知用户 更改已经发布的软件包 使用现成的工具来自动化部署 在没有监控结果的情况下执行展开步骤 使用特性开关逐步推出更新 依赖于顺序部署 使用熔断器防止应用造成重大的破坏 使用影子流量或摸黑启动来进行重大变更
第9章 On-Call
On-Call 的工作方式
- 对事故分流、缓解症状和最终解决
On-Call 技能包
随时响应
保持专注
确定工作优先级
- 优先级分类
- P1:严重影响(critical impact) — 服务在生产环境中无法使用
- P2:高影响(high impact) — 服务的使用受到严重损害
- P3:中等影响(medium impact) — 服务的使用部分受损
- P4:低影响(low impact) — 服务完全可用
- 服务水平指标(SLI):如错误率、请求延迟和每秒请求数
- 服务水平目标(SLO) 为健康的应用程序行为定义了 SLI 的目标
- 服务水平协议(SLA)是关于越过 SLO 范围时将会发生什么的协议
- 优先级分类
清晰的沟通
跟踪你的工作
事故处理
- 事故响应的 5个阶段:分流、协同、应急方案、解决方案、后续行动
行为准则
需要做的 不应该做的 将呼叫你的号码添加到电话联系人的白名单中 无视警告 使用优先级类别、SLI、SLO 和 SLA 来确定事故响应的优先级 在分流阶段就尝试排除故障 针对严重的事故采取分流、协同、应急方案、解决方案、后续行动的策略 在问题尚未缓解的情况下就去做根本原因分析 使用科学的方式去排除故障 在事后回顾总结的时候指责别人 在事故的后续行动环节使用 5W(Why)的方式来追根溯源 对关闭那些无响应的支持请求犹豫 确认响应支持类的请求 询问支持的请求者他们的优先级是什么,不询问问题的影响 针对下一次回复给予明确的时间预期 逞英雄修复所有的事情 在关闭请求类的任务票之前确认问题都已经修改好了 将支持请求重定向到适当的沟通渠道
第10章 技术设计流程
技术设计的 V 形结构
- 队友之间 - 团队内部 - 团队之间(确定性和清晰度 ↑ )
关于设计的思考
- 定义问题
- 着手调查
- 进行实验
- 给些时间
撰写设计文档
- 文档持续变更
- 了解撰写文档的目的
- 学会写作
- 保证文档是最新的
使用设计文档模板
概要
现状与背景
变更的目的
需求
- 面向用户的需求
- 技术需求
- 安全性与合规性需求
- 其他(截至期限、预算)
潜在的解决方案
建议的解决方案
设计与架构
- 系统构成图
- UI (user interface design) / UX (user experience design) 变更点
- 代码变更点
- API 变更点
- 持久层变更点
测试计划
发布计划
遗留的问题
附录
协作设计
- 理解你的团队的设计评审流程
- 不要让人惊讶
- 用设计讨论来进行头脑风暴
- 为设计出力
行为准则
需要做的 不应该做的 使用设计文档模板 在意早晚会变的实验性的代码 阅读博客、论文和–些演讲文稿来获取灵感 只讨论一项解决方案 对于你看到的一切保持批判性思考 让非母语阻止你写作 在设计阶段就编写实验性的代码 在具体实施方案和计划有些偏离时忘记更新设计文档 学会清晰地写作,并经常练习 消极地参与团队设计讨论 对设计文档进行版本控制 对队友的设计提出问题
第11章 构建可演进的架构
理解复杂性
- 高依赖性
- 高隐蔽性
- 高惯性
可演进的设计
- 你不是真的需要(You ain’t gonna need it,YAGNI)
- 最小惊讶原则(别搞一些骚操作⛏)
- 封装专业领域知识
- 领域驱动设计(domain-driven design,DDD)
可演进的 API
保持 API 小巧
- 默认值可使大型 API 在感觉上很小巧
公开定义良好的服务端 API
保持 API 变更的兼容性
API 版本化
- API 版本通常由 API 网关或服务网格来管理
可持续的数据管理
数据库隔离
使用 schema
- 采用无模式的方法会产生明显的数据完整性和复杂性问题
- 不要将无模式的数据隐藏在已经模式化的数据中
schema 自动化迁移
保持 schema 的兼容性
行为准则
需要做的 不应该做的 牢记 YAGNI 原则:“You Aren’t Gonna Need It” 无目的地构建过多的抽象模型 使用标准类库和开发模型 编写隐含排序需求和参数需求的方法 使用 接口定义语言(IDL)来定义你的 API 使用怪异代码让其他开发者感到惊讶 对外部 API 和文档进行版本管理 对 API 进行不兼容的变更 隔离不同应用程序的数据库 对内部 API 的版本控制持教条态度 对所有的数据定义显式的 schema 在字符串或字节字段中嵌入无模式数据 使用迁移工具来进行数据库 schema 的自动化管理 如果下游数据消费者使用到了你的数据,保持 schema 的兼容性
第12章 敏捷计划
(针对的是 项目经理 和 程序经理)
敏捷宣言
- 个人和互动高于流程和工具
- 工作的软件高于详尽的文档
- 客户合作高于合同谈判
- 响应变化高于遵循计划
敏捷计划的框架
- Scrum
- 看板
Scrum 框架
- 用户故事
- 任务分解
- 故事点
- 消化积压
- 冲刺计划
站会(Scrum 会议 / huddle会)
评审机制
回顾会
路线图
- “在准备战斗时,我总是发现计划是无用的,但计划是不可缺少的。”
行为准则
需要做的 不应该做的 保持站会简短 痴迷于敏捷开发的“正确做法” 为用户故事写下详细的验收标准 害怕改变敏捷流程 承诺可以在冲刺迭代中实际完成的工作 将常规任务描述强加给“用户故事” 如果你无法在冲刺迭代中完成大块工作,请将其分解 忘记跟踪计划和设计工作 使用故事点来预估工作量 尚未完成已提交的工作时又在冲刺开始后追加工作 务必使用相对尺度和T恤尺码来帮助估算 盲目地遵循流程
第13章 与管理者合作
管理者是做什么的
- 管理者们构建团队、指导和培养工程师,并进行人际关系的动态管理
- 工程经理还计划和协调产品的开发
- 管理者们通过与高管或董事(“向上”)合作
- 与其他管理者(“横向”)合作
- 与他们的团队(“向下”)合作
沟通、目标与成长
一对一面谈
进展、计划与问题(progress-plans-problems,PPP)
- PPP 是一种常用的更新工作状态的格式
目标、关键和结果(Objective, Key, Result,OKR)
- OKR 框架是公司定义目标和衡量其是否成功的一种方式
关键绩效指标(Key Performance Indicator,KPI)
- 放弃了“O”,只关注关键结果 —关键绩效指标(KPI),而不明确说明目标
绩效考核
- 你今年做了什么?
- 今年有什么事情进展顺利?
- 今年有什么事情可以做得更好?
- 你在职业生涯中想得到什么?你认为自己在3到5年内会到达什么样的高度?
- 不要忘了非工程类的项目
- 辅导实习生、代码评审、参与面试、博客文章、演讲、文档 …
向上管理
接收反馈
给予反馈
- 在提供反馈时,使用情况、行为和影响(situation-behavior-impact,SBI)框架
讨论你的目标
事情不顺时要采取行动
如果你已经给出了反馈意见,并保持了耐心,但事情仍然没有进展,那就起身离开
行为准则
需要做的 不应该做的 期望管理者能够平易近人且具有透明度 向管理者隐瞒困难 明确告知你的管理者你需要什么 仅仅把一对一面谈当作更新工作状态的会议 为一对一面谈设置议程 仅凭记忆进行自我总结 保有一对一面谈的纪要 给予他人肤浅的反馈 按照你希望收到的反馈来撰写具有可操作性的反馈 被 OKR 框住 跟踪工作成果,这样在自我评价时会更容易 将反馈视为攻击 采用 SBI 框架来减少反馈对个人的针对性 忍受糟糕的管理 考虑长期的职业目标
第14章 职业生涯规划
迈向资深之路
- 从初级工程师或软件工程师到资深工程师
- 从资深工程师到主任工程师或首席工程师
职业生涯建议
T 型人才(一专多长)
参加工程师训练营
主导你自己的晋升
换工作需谨慎
自我调节
你的职业生涯是一场马拉松,而不是短跑冲刺 ~